Conserving first integrals via manifold projection#
As we saw in an earlier example, even though heyoka.py is not a symplectic integrator it is nevertheless capable of optimally preserving conserved quantities in dynamical systems.
In order to conserve dynamical invariants, heyoka.py needs to be configured to operate at very low tolerances (i.e., below machine epsilon). High-precision numerical integrations however are computationally expensive, and in some contexts it is preferable, for performance reasons, to maintain a low integration accuracy while at the same time ensuring that the global dynamical invariants are preserved. This is the main reason why symplectic integrators are the tool of choice, for instance, in numerical studies of the long-term stability of extrasolar planetary systems.
In this example, we will show how we can enforce the conservation of dynamical invariants in high-tolerance numerical integrations with heyoka.py via a technique known as manifold projection.
Setting things up#
We will re-use here the setup described in the outer Solar System example: a gravitational 6-body problem consisting of the Sun, Jupiter, Saturn, Uranus, Neptune and Pluto with realistic initial conditions.
Let us begin by defining a few constants and the initial conditions:
import heyoka as hy
import numpy as np
# Masses, from Sun to Pluto.
masses = np.array(
[1.00000597682, 1 / 1047.355, 1 / 3501.6, 1 / 22869.0, 1 / 19314.0, 7.4074074e-09]
)
# The gravitational constant.
G = 0.01720209895 * 0.01720209895 * 365 * 365
# Initial conditions.
ic = [ # Sun.
-4.06428567034226e-3,
-6.08813756435987e-3,
-1.66162304225834e-6,
+6.69048890636161e-6 * 365,
-6.33922479583593e-6 * 365,
-3.13202145590767e-9 * 365,
# Jupiter.
+3.40546614227466e0,
+3.62978190075864e0,
+3.42386261766577e-2,
-5.59797969310664e-3 * 365,
+5.51815399480116e-3 * 365,
-2.66711392865591e-6 * 365,
# Saturn.
+6.60801554403466e0,
+6.38084674585064e0,
-1.36145963724542e-1,
-4.17354020307064e-3 * 365,
+3.99723751748116e-3 * 365,
+1.67206320571441e-5 * 365,
# Uranus.
+1.11636331405597e1,
+1.60373479057256e1,
+3.61783279369958e-1,
-3.25884806151064e-3 * 365,
+2.06438412905916e-3 * 365,
-2.17699042180559e-5 * 365,
# Neptune.
-3.01777243405203e1,
+1.91155314998064e0,
-1.53887595621042e-1,
-2.17471785045538e-4 * 365,
-3.11361111025884e-3 * 365,
+3.58344705491441e-5 * 365,
# Pluto.
-2.13858977531573e1,
+3.20719104739886e1,
+2.49245689556096e0,
-1.76936577252484e-3 * 365,
-2.06720938381724e-3 * 365,
+6.58091931493844e-4 * 365,
]
See the outer Solar System example for more details on the setup.
Next, we setup the dynamical equations of our N-body problem:
# Define the ODEs.
sys = hy.model.nbody(6, masses=masses, Gconst=G)
We also store the 36 state variables (3 Cartesian positions and 3 Cartesian velocities for each of the 6 bodies) in a list for later use:
state_vars = [p[0] for p in sys]
Next, we define a compiled function for the rapid computation of the energy of the system from the state vector. Here we are using the model.nbody_energy() helper, which creates the symbolic formula for the energy constant in the N-body problem:
# Define a compiled function for the computation
# of the energy in an N-body system from its state vector.
en_cfunc = hy.cfunc(
[hy.model.nbody_energy(6, masses=masses, Gconst=G)], vars=state_vars
)
We can now proceed to the instantiation of the numerical integrator. We choose a high tolerance of \(10^{-6}\), so that the integrator will not be able to enforce energy conservation on its own (since we are not operating at sub-epsilon tolerances):
ta = hy.taylor_adaptive(sys, ic, tol=1e-6)
Let us now compute the initial energy of the system:
print(f"Initial energy: {en_cfunc(ta.state)[0]}")
Initial energy: -0.004286848855986956
So far so good (though perhaps not very exciting).
The next step is the introduction of a callback to be invoked after every step taken by the numerical integrator. This callback will check the relative energy error, and stop the integration if the error exceeds the \(10^{-6}\) threshold:
class proj_callback:
def __init__(self, ta):
# Store the initial energy value
# as a data member.
self.E0 = en_cfunc(ta.state)[0]
def __call__(self, ta):
# Compute the relative energy error
# wrt the initial energy value.
rel_err = abs((en_cfunc(ta.state)[0] - self.E0) / self.E0)
# Stop if the error is greater than 1e-6.
if rel_err > 1e-6:
print(f"Rel energy error: {rel_err}")
return False
else:
return True
Let us now integrate until the energy error reaches the threshold:
cb = proj_callback(ta)
# Attempt to propagate the state of the
# system for 1000 years.
ta.propagate_until(1000.0, callback=cb)
Rel energy error: 1.1480506378333837e-06
(<taylor_outcome.cb_stop: -4294967301>,
0.7296940138544907,
1.0583722519817733,
36,
None,
<__main__.proj_callback at 0x7f8234210c80>)
We can see from the output that indeed the integration was terminated earlier because of the callback (as indicated by the taylor_outcome.cb_stop outcome), and that the error threshold was exceeded after 36 steps.
Fixing the energy#
We can now move to the interesting part, that is, enforcing energy conservation. The basic idea is to alter the current state vector of the system (whose energy has drifted away from the initial value) so that the energy of the updated state vector matches the initial energy of the system.
Because there are infinite points in phase space whose energy is equal to the initial value, we impose the additional constraint that the updated state vector should be as close as possible to the original one. In other words, we are projecting the position in phase space of the current state vector onto the hyper-surface (manifold) defined by the conservation of energy.
This projection process can be seen as a constrained optimisation problem: we want to minimise the distance from the original state vector subject to the constraint that the updated state vector must lie on the manifold defined by the conservation of energy.
Let us begin with the definition of the objective function:
def objfun(x):
return np.sum((x - ta.state) ** 2)
As mentioned above, here we are trying to minimise the distance (in phase space) between the original state vector (ta.state) and the updated state vector (x).
Next, we define the constraint:
def cstr_fun(x):
return en_cfunc(x)[0] - cb.E0
This equality constraint is satisifed if cstr_fun() returns zero, that is, if the energy of the updated state vector (x) is equal to the initial energy of the system (stored in the callback as cb.E0).
We are now ready to run the optimisation via scipy.optimize.minimize(). Note that we need an optimiser with support for constraints (here we choose 'SLSQP'):
from scipy.optimize import minimize
ret = minimize(
objfun,
ta.state,
method="SLSQP",
tol=1e-10,
constraints=[{"type": "eq", "fun": cstr_fun}],
)
# Store the updated state vector.
res = ret.x
print(ret)
message: Optimization terminated successfully
success: True
status: 0
fun: 1.6028684336487322e-12
x: [ 3.841e-04 4.208e-03 ... -1.215e+00 5.875e-02]
nit: 2
jac: [ 3.113e-08 -4.027e-07 ... 7.717e-11 7.411e-11]
nfev: 76
njev: 2
multipliers: [-6.498e-04]
We can see how the optimisation terminated successfully.
Let us verify that the updated state vector (res) conserves energy with a better accuracy than the original state vector:
print(f"Original energy error: {abs((en_cfunc(ta.state)[0] - cb.E0) / cb.E0)}")
print(f"Updated energy error: {abs((en_cfunc(res)[0] - cb.E0) / cb.E0)}")
Original energy error: 1.1480506378333837e-06
Updated energy error: 1.394727192241754e-11
Helping the optimiser out#
Optimisation algorithms can greatly benefit from the availability of gradients for the objective function and the constraints. Luckily, heyoka.py’s expression system lets us compute derivatives without too much pain.
Let us begin by defining a symbolic expression representing the square of the distance between the original state vector and the updated state vector. Here, the original state vector will be represented by the symbolic state variables (stored earlier in state_vars) and the updated state vector will be passed in the array of runtime parameters:
dist2_ex = hy.sum(list((state_vars[i] - hy.par[i]) ** 2 for i in range(36)))
Let us take a look at dist2_ex just to fix the ideas:
dist2_ex
((x_0 - p0)**2.0000000000000000 + (y_0 - p1)**2.0000000000000000 + (z_0 - p2)**2.0000000000000000 + (vx_0 - p3)**2.0000000000000000 + (vy_0 - p4)**2.0000000000000000 + (vz_0 - p5)**2.0000000000000000 + (x_1 - p6)**2.0000000000000000 + (y_1 - p7)**2.0000000000000000 + (z_1 - p8)**2.0000000000000000 + (vx_1 - p9)**2.0000000000000000 + (vy_1 - p10)**2.0000000000000000 + (vz_1 - p11)**2.0000000000000000 + (x_2 - p12)**2.0000000000000000 + (y_2 - p13)**2.0000000000000000 + (z_2 - p14)**2.0000000000000000 + (vx_2 - p15)**2.0000000000000000 + (vy_2 - p16)**2.0000000000000000 + (vz_2 - p17)**2.0000000000000000 + (x_3 - p18)**2.0000000000000000 + (y_3 - p19)**2.0000000000000000 + (z_3 - p20)**2.0000000000000000 + (vx_3 - p21)**2.0000000000000000 + (vy_3 - p22)**2.0000000000000000 + (vz_3 - p23)**2.0000000000000000 + (x_4 - p24)**2.0000000000000000 + (y_4 - p25)**2.0000000000000000 + (z_4 - p26)**2.0000000000000000 + (vx_4 - p27)**2.0000000000000000 + (vy_4 - p28)**2.0000000000000000 + (vz_4 - p29)**...
We can now compute symbolically the gradient vector of dist2_ex:
grad_dist2_ex = list(hy.diff(dist2_ex, state_vars[i]) for i in range(36))
grad_dist2_ex
[(2.0000000000000000 * (x_0 - p0)),
(2.0000000000000000 * (y_0 - p1)),
(2.0000000000000000 * (z_0 - p2)),
(2.0000000000000000 * (vx_0 - p3)),
(2.0000000000000000 * (vy_0 - p4)),
(2.0000000000000000 * (vz_0 - p5)),
(2.0000000000000000 * (x_1 - p6)),
(2.0000000000000000 * (y_1 - p7)),
(2.0000000000000000 * (z_1 - p8)),
(2.0000000000000000 * (vx_1 - p9)),
(2.0000000000000000 * (vy_1 - p10)),
(2.0000000000000000 * (vz_1 - p11)),
(2.0000000000000000 * (x_2 - p12)),
(2.0000000000000000 * (y_2 - p13)),
(2.0000000000000000 * (z_2 - p14)),
(2.0000000000000000 * (vx_2 - p15)),
(2.0000000000000000 * (vy_2 - p16)),
(2.0000000000000000 * (vz_2 - p17)),
(2.0000000000000000 * (x_3 - p18)),
(2.0000000000000000 * (y_3 - p19)),
(2.0000000000000000 * (z_3 - p20)),
(2.0000000000000000 * (vx_3 - p21)),
(2.0000000000000000 * (vy_3 - p22)),
(2.0000000000000000 * (vz_3 - p23)),
(2.0000000000000000 * (x_4 - p24)),
(2.0000000000000000 * (y_4 - p25)),
(2.0000000000000000 * (z_4 - p26)),
(2.0000000000000000 * (vx_4 - p27)),
(2.0000000000000000 * (vy_4 - p28)),
(2.0000000000000000 * (vz_4 - p29)),
(2.0000000000000000 * (x_5 - p30)),
(2.0000000000000000 * (y_5 - p31)),
(2.0000000000000000 * (z_5 - p32)),
(2.0000000000000000 * (vx_5 - p33)),
(2.0000000000000000 * (vy_5 - p34)),
(2.0000000000000000 * (vz_5 - p35))]
Shocking, I know.
We can now proceed to create a compiled function that will concatenate in a single vector output the value of the distance square and its gradient vector:
objfun_cfunc = hy.cfunc([dist2_ex] + grad_dist2_ex, vars=state_vars)
Finally, we can define an updated objective function that, in addition to returning the distance square, will return also its gradient vector (in the format required by scipy.optimize.minimize(), i.e., as a tuple of 2 values):
def objfun(x):
ret = objfun_cfunc(x, pars=ta.state)
# Return the distance square and its
# gradient as a tuple of 2 values.
return (ret[0], ret[1:])
In a similar fashion, we can define a compiled function for the computation of the gradient of the constraint:
# The symbolic expression representing the energy
# of the system.
en_ex = hy.model.nbody_energy(6, masses=masses, Gconst=G)
# The gradient of the energy.
grad_cstr = list(hy.diff(en_ex, state_vars[i]) for i in range(36))
# The compiled function for the computation of the gradient
# of the constraint.
grad_cstr_cfunc = hy.cfunc(grad_cstr, vars=state_vars)
We can now put everything together, and invoke again scipy.optimize.minimize() supplying the gradients:
ret = minimize(
objfun,
ta.state,
method="SLSQP",
tol=1e-10,
jac=True,
constraints=[{"type": "eq", "fun": cstr_fun, "jac": grad_cstr_cfunc}],
)
res = ret.x
print(ret)
message: Optimization terminated successfully
success: True
status: 0
fun: 1.6028685205666326e-12
x: [ 3.841e-04 4.208e-03 ... -1.215e+00 5.875e-02]
nit: 2
jac: [ 3.120e-08 -4.048e-07 ... 2.930e-12 -1.417e-13]
nfev: 4
njev: 2
multipliers: [-6.514e-04]
Like before, the optimisation completed successfully, this time taking far fewer objective function evaluations thanks to the availability of the gradient (which was previously estimated via numerical differencing).
We can again verify that the updated state vector (res) conserves energy with a better accuracy than the original state vector:
print(f"Original energy error: {abs((en_cfunc(ta.state)[0] - cb.E0) / cb.E0)}")
print(f"Updated energy error: {abs((en_cfunc(res)[0] - cb.E0) / cb.E0)}")
Original energy error: 1.1480506378333837e-06
Updated energy error: 1.3841857553804836e-11
Packaging it all together#
As a last step, we now incorporate manifold projection into the step callback, so that we can automatically ensure energy conservation whenever the energy error drifts too far during the numerical integration.
Here is the updated version of the callback:
class proj_callback:
def __init__(self, ta):
# Store the initial energy value
# as a data member.
self.E0 = en_cfunc(ta.state)[0]
# Setup a variable to count how many times
# we perform manifold projection.
self.n_proj = 0
def __call__(self, ta):
# Compute the relative energy error
# wrt the initial energy value.
rel_err = abs((en_cfunc(ta.state)[0] - self.E0) / self.E0)
# Fix the energy if the error is greater than 1e-6.
if rel_err > 1e-6:
ret = minimize(
objfun,
ta.state,
method="SLSQP",
tol=1e-10,
jac=True,
constraints=[{"type": "eq", "fun": cstr_fun, "jac": grad_cstr_cfunc}],
)
if ret.status != 0:
print(f"Optimisation returned nonzero status:\n{ret}")
return False
# Update the state vector.
ta.state[:] = ret.x
# Update the counter.
self.n_proj += 1
return True
Let us now reset the state of the integrator back to the original initial conditions:
ta.state[:] = ic
ta.time = 0.0
We are now ready to repeat the numerical integration with automatic manifold projection. We will propagate the state of the system over an equispaced time grid up to \(10^5\) years:
# Create the callback object.
cb = proj_callback(ta)
# Define the time grid.
t_grid = np.linspace(0, 1e5, 1000)
# Run the numerical integration.
pres_proj = ta.propagate_grid(t_grid, callback=cb)
Let us also run a numerical integration without projection for comparison:
ta.state[:] = ic
ta.time = 0.0
pres_noproj = ta.propagate_grid(t_grid)
We can now take a look at the results:
from matplotlib.pylab import plt
fig = plt.figure(figsize=(12, 6))
# Use log scale on the y axis.
plt.yscale("log")
# Compute the energy error over the time grid.
en_proj_hist = en_cfunc(np.ascontiguousarray(pres_proj[-1].transpose()))
err_proj_hist = abs((cb.E0 - en_proj_hist[0]) / cb.E0)
err_noproj_hist = en_cfunc(np.ascontiguousarray(pres_noproj[-1].transpose()))
err_noproj_hist = abs((cb.E0 - err_noproj_hist[0]) / cb.E0)
plt.plot(t_grid, err_proj_hist, marker=".", linestyle="None", label="With projection")
plt.plot(
t_grid, err_noproj_hist, marker=".", linestyle="None", label="Without projection"
)
plt.xlabel("Time (years)")
plt.ylabel("Rel. energy error")
plt.legend()
plt.tight_layout();
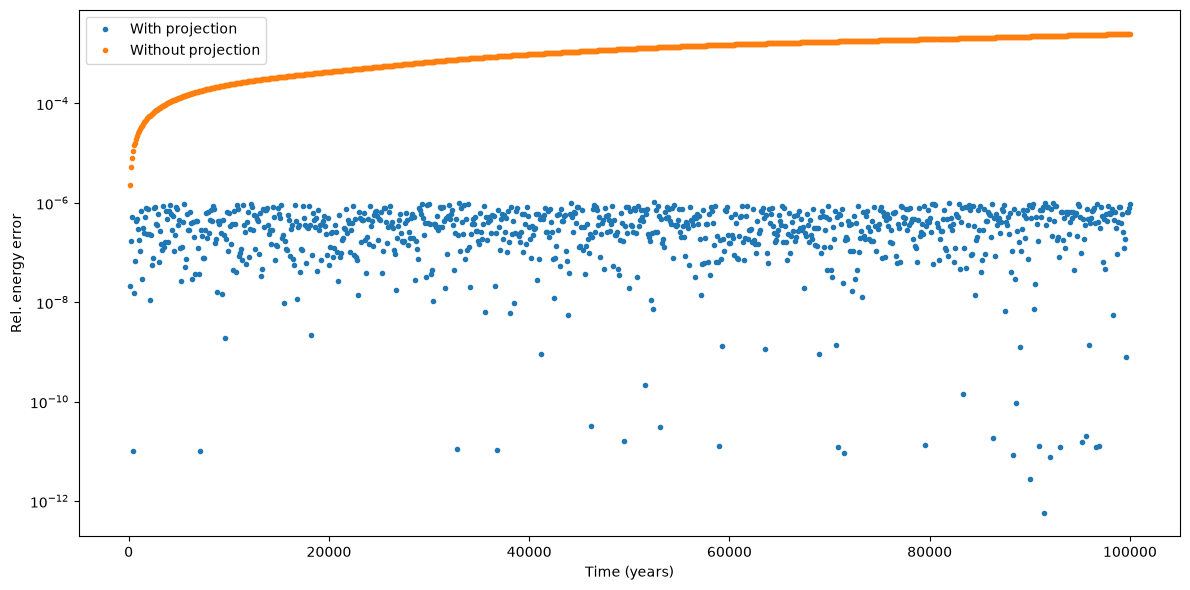
We can indeed see how the energy error with projection is kept under the \(10^{-6}\) threshold.
We can also take a look at the number of manifold projections performed throughout the integration and compare it to the total number of steps:
print(f"Number of projections: {cb.n_proj}")
print(f"Number of steps: {pres_proj[3]}")
Number of projections: 3765
Number of steps: 108881